UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字元编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字元,且其编码中的第一个位元组仍和ASCII相容,这使得原来处理ASCII字元的软件无需或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
在计算机体系里,无论是硬盘中的文件,网络上的页面,还是我们的电子邮件,所有的数据在底层都是一堆01串,为什么数据都可以按照10串的形式存储或者传输,就是因为有编码的存在,我们平常所说的编码方式就是一种将我们熟悉的符号翻译成对应的01串的规则。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码 )是上世纪60年代美国制定的一套编码规则,一直沿用至今。ASCII码中一共定义了128个字符对应的编码,如下图所示:
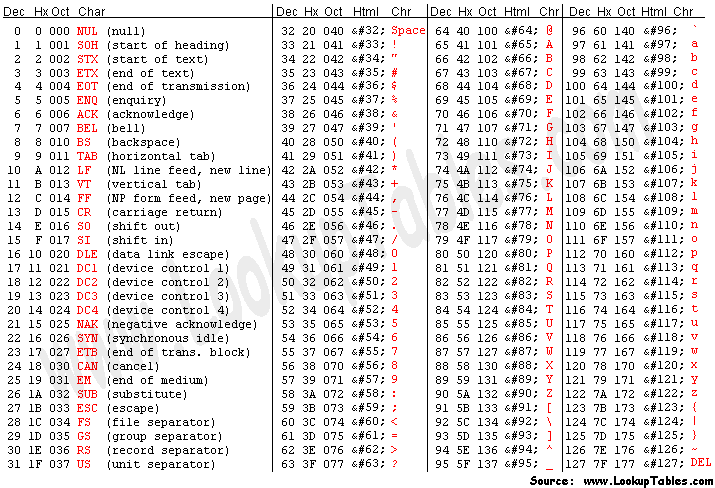
对于英语,128个字符是够用了,但是对于其他语言如法语、俄语、汉语,128个字符是远远不够用的,很多欧洲国家都对ASCII码进行了扩展,但是不同的国家使用不同的编码,我们想要打开不同国家的文件,就需要知道这个文件对应的编码方式,否则就会出现乱码,如果有一种编码,将世界上所有的符号都纳入其中,给每一个符号定义一个独一无二的编码,那就会解决乱码的问题了,Unicode码就是这样的一种符号编码,Unicode是一个很大的集合,可以容纳100多万个符号,每个符号对应唯一的编码。由于定义的符号数量巨大,所以每个符号的编码可能需要1~4个字节来存储。
Unicode只是一个编码集合,它定义了符号和编码的对应关系,但是没有定义怎样存储这些符号,UTF-8中定义了这些符号应该怎样存储。
UTF-8是互联网上使用最广泛的一种Unicode的实现方式,它是一种变长的编码方式可以使用1~4表示一个符号,根据不同的符号变化字节的长度,UTF-8的编码规则如下表所示:
| 码点位数 | 码点范围 | 字节序列 | Byte1 | Byte2 | Byte3 | Byte4 | Byte5 | Byte6 |
|---|---|---|---|---|---|---|---|---|
| 7 | 0000~007F | 1 | 0xxxxxxx | |||||
| 11 | 0080~07FF | 2 | 110xxxxx | 10xxxxxx | ||||
| 16 | 0800~FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 21 | 10000~1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 26 | 200000~3FFFFFF | 5 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 31 | 4000000~7FFFFFFF | 6 | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
上表中x代表可以存储编码的位,由上表可以看到UTF-8的编码规则非常简单:
- 对于单字节的符号,字节的第一位设置为0,后买7为是这个符号的Unicode码。因此对于英语,UTF-8和ASCII码是相同的。
- 对于n > 1个字节的符号,第一个字节最高位1的个数代表编码的字节数,剩下的字节每个字节以10开头。
有了UTF-8定义的编码存储方式,我们拿到一段编码后就能清楚的看到这段编码由多少字节组成,每一个字节中编码的内容,得到字符编码后,通过查询Unicode编码表我们就可以得知这个符号是什么了。
参考:UTF-8